Supporting Time Series Processing With Meteoio
by Mathias Bavay. Contributors Sabrina Hereema and Oda Mulelid | Published: 08-Sep-25 | Last updated: 08-Sep-25 | Tags : tool weather | category: NEWS
The challenge
Scientific
research depends on data—from lab experiments to weather measurements, medical
studies, and even space missions. Yet, collecting scientific data is often expensive,
time-consuming, and sometime impossible to reproduce. You can’t, for instance,
rerun the passage of an interstellar object through our solar system.
That’s what
makes data so valuable. When shared and reused, a single dataset can fuel new
discoveries across different disciplines—even decades after it was first
collected.
The FAIR principles (Findable, Accessible, Interoperable, Reusable) provide a framework for effective data sharing. But in practice, applying them is challenging, and researchers rearly receive recognition for doing so. So the question is: how can we make FAIR data sharing easier and more worthwhile?
Our
answer: The MeteoIO Web Service
We created the
MeteoIO Web Service to simplify and improve data management for automatically
measured timeseries (such as weather station data).
It tackles
two key challenges:
- Making data FAIR: reducing the effort and cost
for researchers to publish and maintain high-quality, reusable datasets.
- Adding direct value: ensuring that researchers themselves gain tangible benefits from sharing their data.
Supporting day to day scientific data acquisition
Collecting long-term data is demanding: instruments require constant maintenance, file formats evolve, and metadata is often incomplete. Without proper documentation, valuable datasets risk becoming unusable. Problems such as faulty sensors may remain hidden for years, and by the time someone tries to reuse the data, the necessary context is often missing.
Even when
the data is available, researchers usually face a laborious process of
cleaning, standardizing, and documenting it before it can be analysed. These
tasks are not only tedious but also divert time and resources away from actual
research.
The MeteoIO Web Service manages the entire data lifecycle, from raw sensor output to publication-ready datasets. It runs data through a five-step pipeline:
1. Read & convert raw data into a standard format.
2. Organise & merge sources, rename parameters, etc.
3. Filter & correct errors in the data.
4. Resample if needed (e.g. adjust time intervals)
5. Export datasets in chosen formats with rich metadata

An illustration of how the MeteoIO processes data
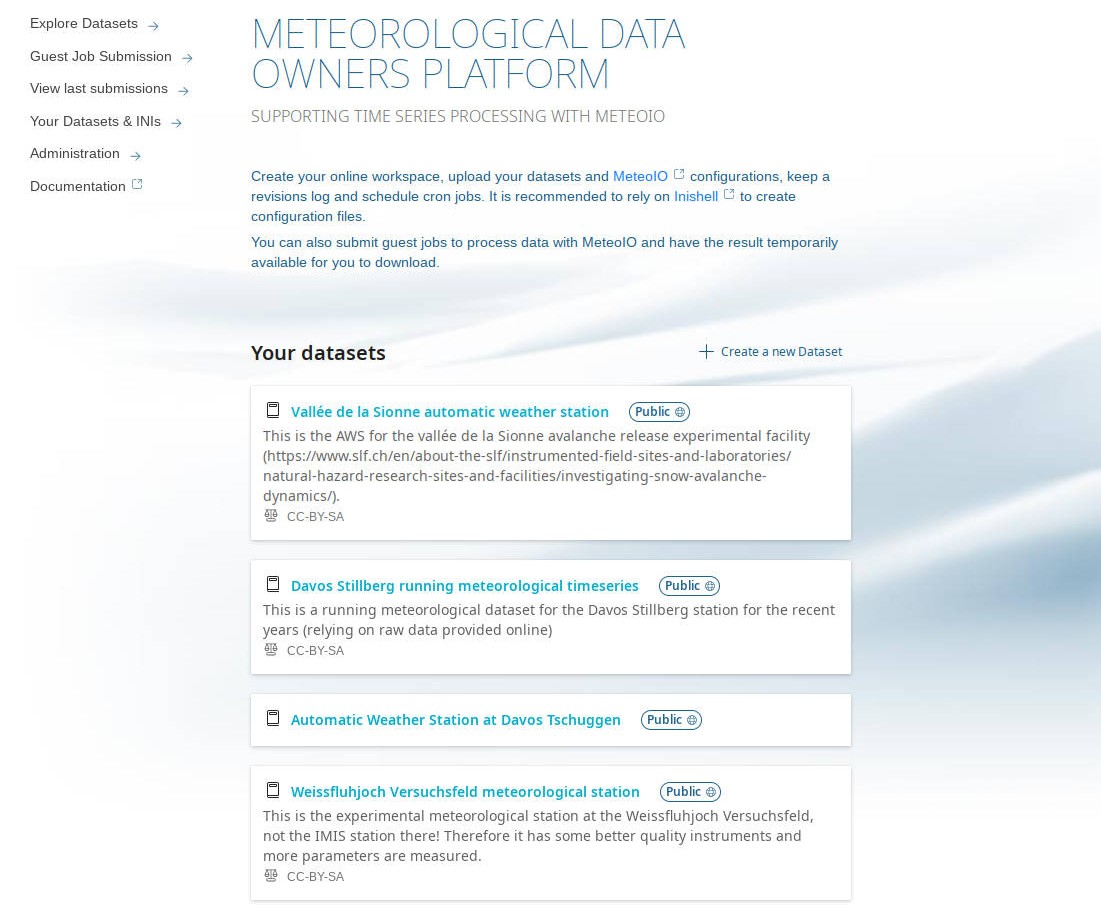
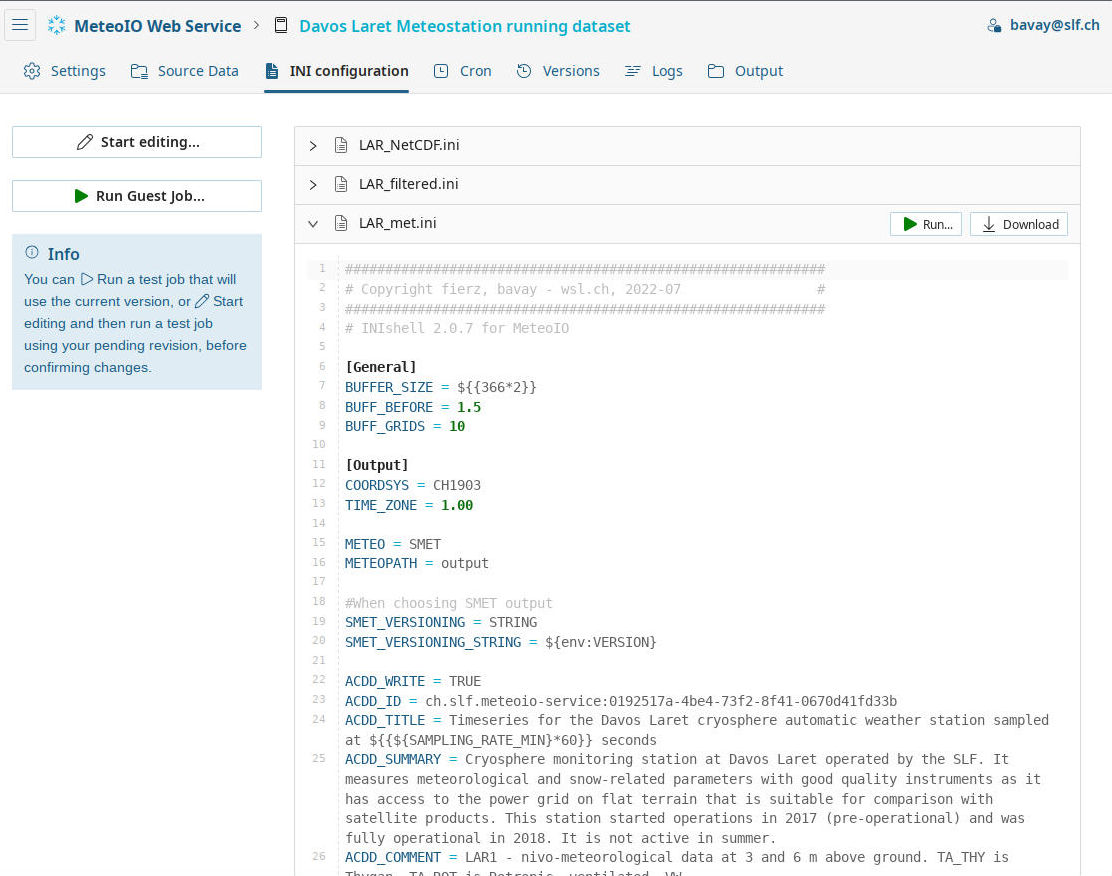 When entering MeteO you can upload and process your datasets (left). A configuration file automatically records every step, making the process reproducible (right: What a data owner sees about data configuration).
When entering MeteO you can upload and process your datasets (left). A configuration file automatically records every step, making the process reproducible (right: What a data owner sees about data configuration).
How Researchers Benefit
- A simple web interface to upload data or connect repositories, configure processing pipelines, and monitor data quality.
- Automatic metadata enrichment that ensures datasets are interoperable and reusable.
- Easy access for others to download public datasets or regenerate them with custom settings.
In short: less work for data owners, higher quality for data users.
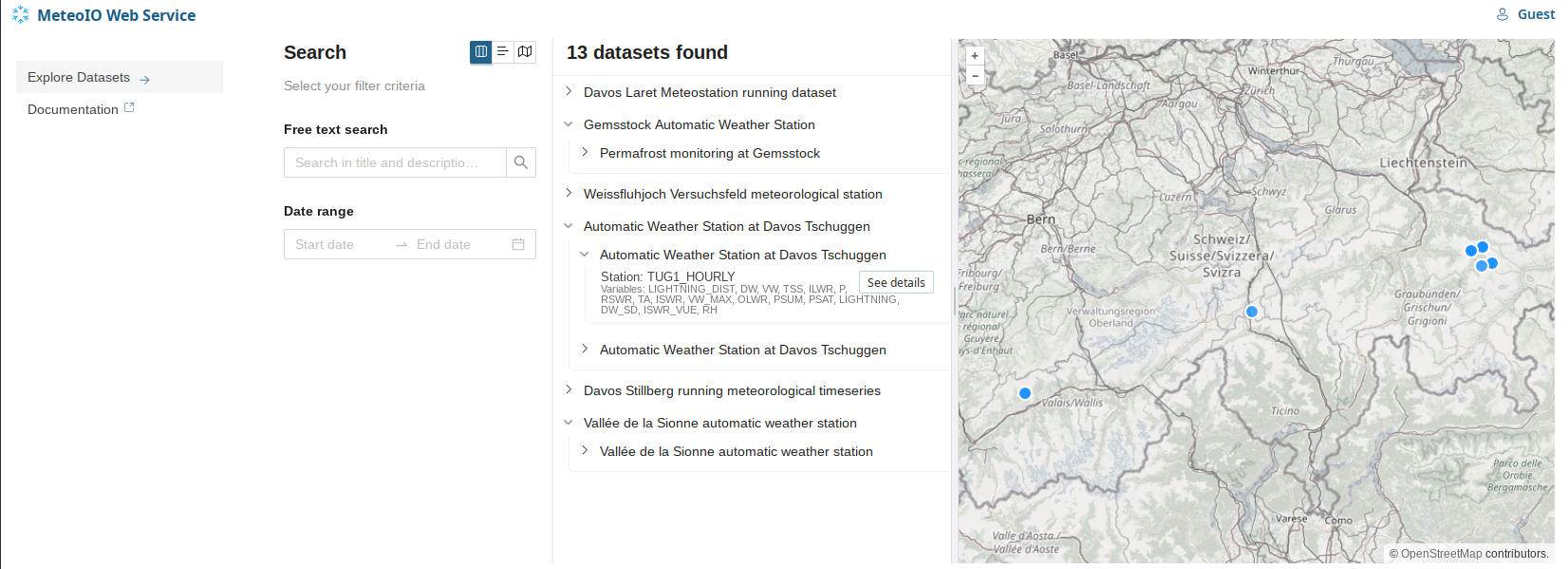 Using the service, you can explore datasets that are reliable.
Using the service, you can explore datasets that are reliable.
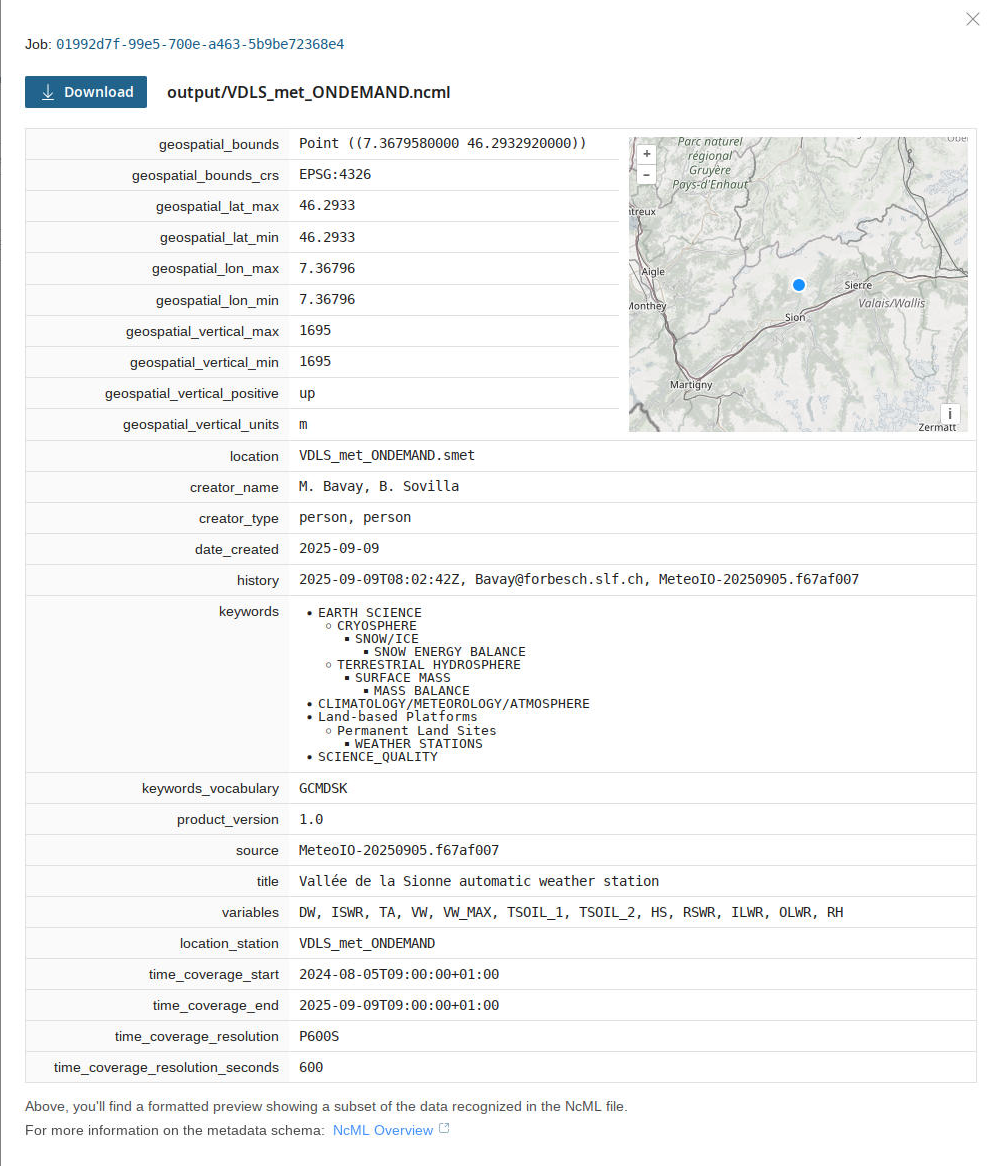
An example of the file for download after data processing (left). An example of scheduling data processing for data that is captured automatically (right).
Want to learn more?
If you have any questions, feedback, or would simply like to learn more about MeteoIO, please contact Mathias Bavay at bavay@slf.ch